f_greedy <- function(data, n) {
dmat <- as.matrix(stats::dist(data))
ind <- integer(n)
ind[1:2] <- as.vector(arrayInd(which.max(dmat), .dim = dim(dmat)))
for (i in 3:n) {
mm <- dmat[ind, -ind, drop = FALSE]
k <- which.max(mm[(1:ncol(mm) - 1) * nrow(mm) + max.col(t(-mm))])
ind[i] <- as.numeric(dimnames(mm)[[2]][k])
}
ind
}
f_new <- function(dat, n) {
dmat <- as.matrix(stats::dist(data))
r <- sample.int(nrow(dmat), n)
repeat {
r_old <- r
for (i in 1:n) {
mm <- dmat[r[-i], -r[-i], drop = FALSE]
k <- which.max(mm[(1:ncol(mm) - 1) * nrow(mm) + max.col(t(-mm))])
r[i] <- as.numeric(dimnames(mm)[[2]][k])
}
if (identical(r_old, r)) return(r)
}
}Finding the Farthest Points in a Point Cloud
r
qualpalr
data visualization
geometry
An algorithm for finding the most separated points in a cloud of points.
My R package qualpalr selects qualitative colors by projecting a bunch of colors (as points) to the three-dimensional DIN99d color space wherein the distance between any pair colors approximate their differences in appearance. The package then tries to choose the n colors so that the minimal pairwise distance among them is maximized, that is, we want the most similar pair of colors to be as dissimilar as possible.
This turns out to be much less trivial that one would suspect, which posts on Computational Science, MATLAB Central, Stack Overflow, and and Computer Science can attest to.
Up til now, qualpalr solved this problem with a greedy approach. If we, for instance, want to find n points we did the following.
M <- Compute a distance matrix of all points in the sample
X <- Select the two most distant points from M
for i = 3:n
X(i) <- Select point in M that maximize the
mindistance to all points in XIn R, this code looked like this (in two dimensions):
set.seed(1)
# find n points
n <- 3
mat <- matrix(runif(100), ncol = 2)
dmat <- as.matrix(stats::dist(mat))
ind <- integer(n)
ind[1:2] <- as.vector(arrayInd(which.max(dmat), .dim = dim(dmat)))
for (i in 3:n) {
mm <- dmat[ind, -ind, drop = FALSE]
k <- which.max(mm[(1:ncol(mm) - 1) * nrow(mm) + max.col(t(-mm))])
ind[i] <- as.numeric(dimnames(mm)[[2]][k])
}
plot(mat, asp = 1, xlab = "", ylab = "")
plot(mat, asp = 1, xlab = "", ylab = "")
points(mat[ind, ], pch = 19)
text(mat[ind, ], adj = c(0, -1.5))
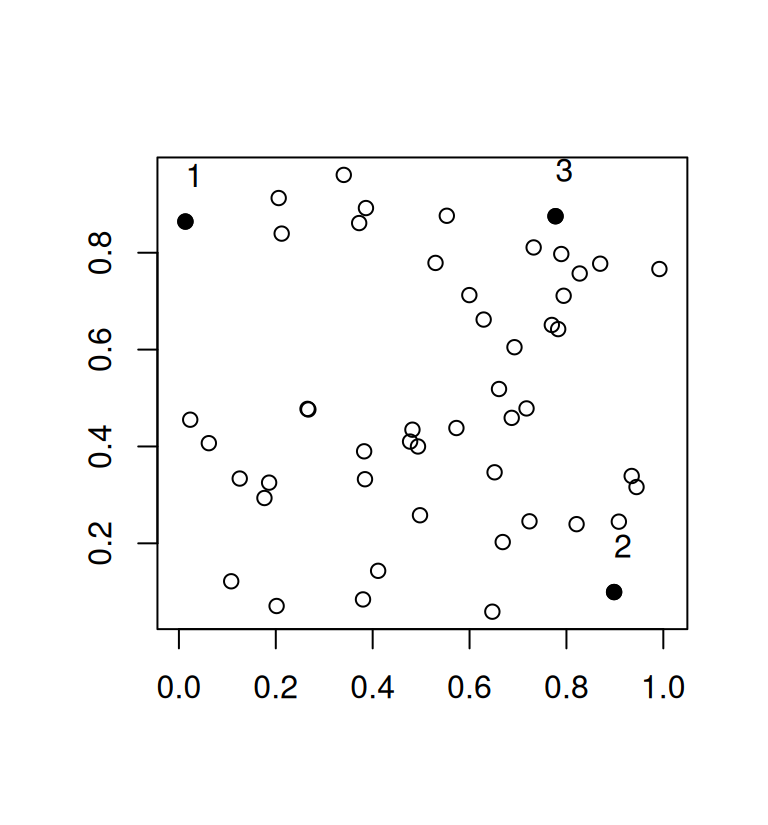
While this greedy procedure is fast and works well for large values of n it is quite inefficient in the example above. It is plain to see that there are other subsets of 3 points that would have a larger minimum distance but because we base our selection on the previous 2 points that were selected to be maximally distant, the algorithm has to pick a suboptimal third point. The minimum distance in our example is 0.7641338.
The solution I came up with is based on a solution from Schlomer et al. (Schlömer, Heck, and Deussen 2011) who devised of an algorithm to partition a sets of points into subsets whilst maximizing the minimal distance. They used delaunay triangulations but I decided to simply use the distance matrix instead. The algorithm works as follows.
M <- Compute a distance matrix of all points in the sample
S <- Sample n points randomly from M
repeat
for i = 1:n
M <- Add S(i) back into M
S(i) <- Find point in M\S with max mindistance to any point in S
until M did not changeIteratively, we put one point from our candidate subset (S) back into the original se (M) and check all distances between the points in S to those in M to find the point with the highest minimum distance. Rinse and repeat until we are only putting back the same points we started the loop with, which always happens. Let’s see how this works on the same data set we used above.
r <- sample.int(nrow(dmat), n)
repeat {
r_old <- r
for (i in 1:n) {
mm <- dmat[r[-i], -r[-i], drop = FALSE]
k <- which.max(mm[(1:ncol(mm) - 1) * nrow(mm) + max.col(t(-mm))])
r[i] <- as.numeric(dimnames(mm)[[2]][k])
}
if (identical(r_old, r)) break
}
plot(mat, asp = 1, xlab = "", ylab = "")
plot(mat, asp = 1, xlab = "", ylab = "")
points(mat[r, ], pch = 19)
text(mat[r, ], adj = c(0, -1.5))
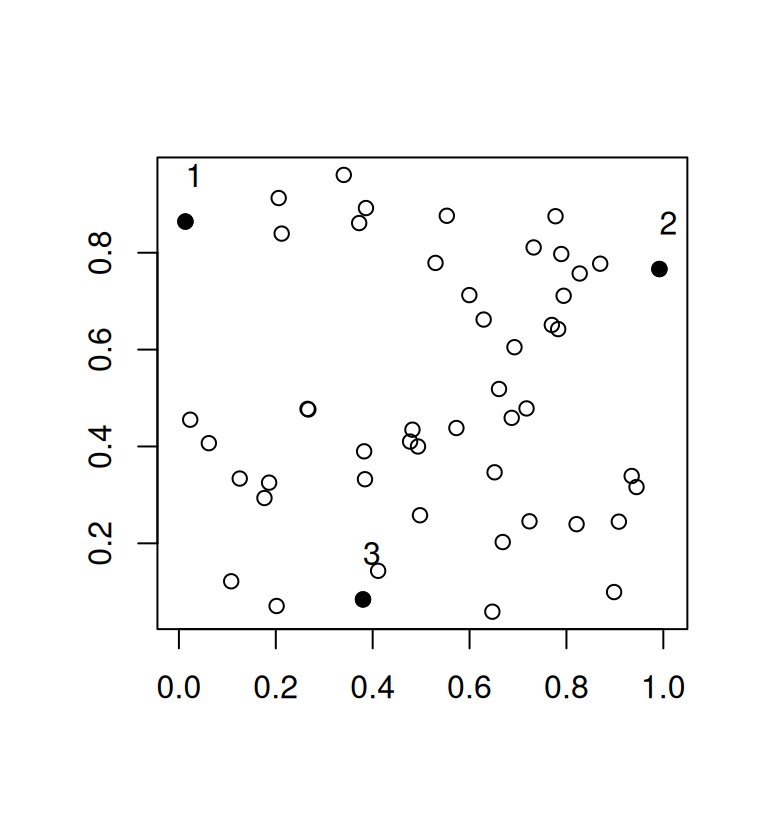
Here, we end up with a minimum distance of 0.8619587. In qualpalr, this means that we now achieve slightly more distinct colors.
Performance
The new algorithm is slightly slower than the old, greedy approach and slightly more verbose
n <- 5
data <- matrix(runif(900), ncol = 3)
microbenchmark::microbenchmark(
f_greedy(data, n),
f_new(data, n),
times = 1000L
)Unit: milliseconds
expr min lq mean median uq max neval
f_greedy(data, n) 1.435719 1.510849 1.727420 1.524154 1.566524 13.80310 1000
f_new(data, n) 1.771449 2.107221 2.646071 2.364280 2.677848 37.38643 1000
cld
a
bThe newest development version of qualpalr now uses this updated algorithm which has also been generalized and included as a new function in my R package euclidr called farthest_points.
References
Schlömer, Thomas, Daniel Heck, and Oliver Deussen. 2011. “Farthest-Point Optimized Point Sets with Maximized Minimum Distance.” In, 135. ACM Press. https://doi.org/bpmnsh.